Original date published: March 3, 2024
Finetuning LLMs for agentic behaviour
A review of the FireAct paper and projection of whats next in large agentic models
The year 2023 was Year 0 for LLMs, It was the year the world got introduced to the power of Large Language Models (LLMs). Since then, industry and academia have worked to explore the full capabilities of these models. Entering Year 1 of LLMs we have seen various new applications and experiments that been developed using LLMs, the most promising of those being Language Agents.
Language agents are software agents which leverage the reasoning capabilities and generalization of LLMs to perceive, plan and take actions in their environment. This particular application of LLMs have gathered the most attention due to its potential to change the structure of the digital economy.
Being in the early stages of this transformational technology, we are yet to develop standards and protocols for building such applications. New frameworks such as ReAct[2] have been developed to fill that gap by describing a prompting framework for instructing and guiding LLMs to cosistently behave like language agents.
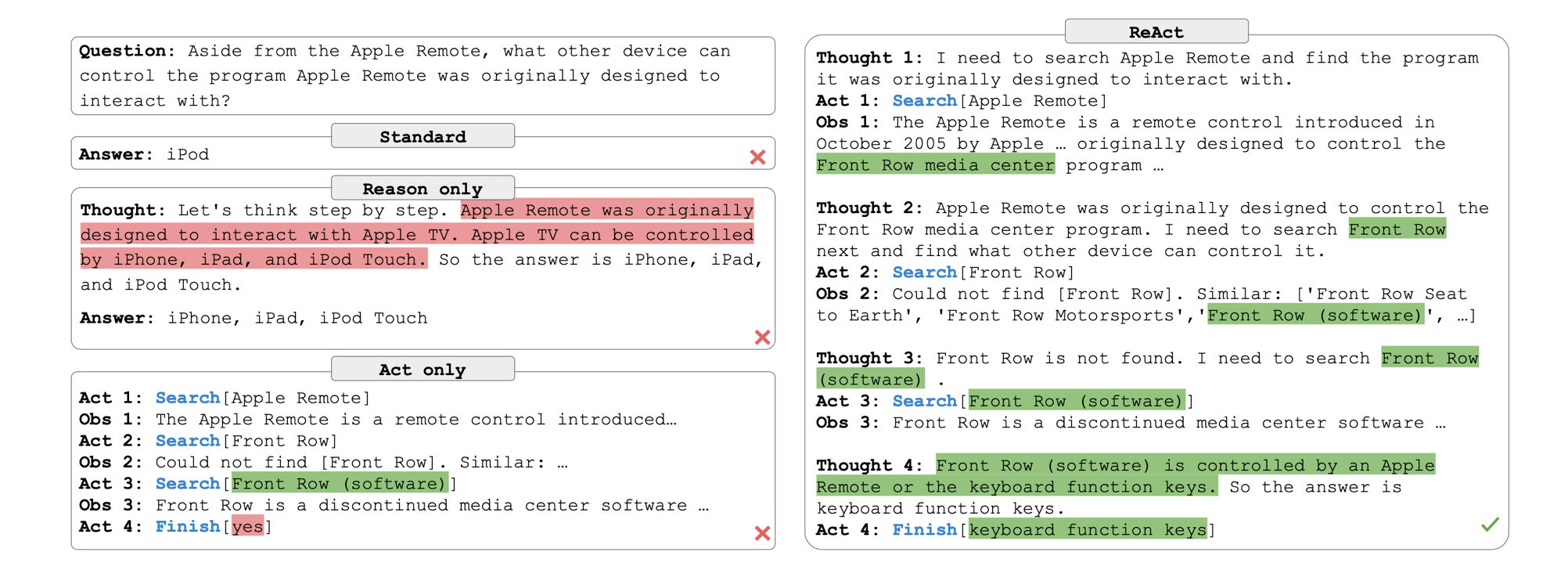
ReAct Agent Framework[1]
The fundamental capability of a language agent is its ability to interact with tools and receive observations from its environment, this capability is crystalized in the ReAcT framework which utilizes reasoning, acting and observing using language models to enable agentic behaviour.
This approch has led to the development of some successful scientific experiments such as Genrative Agents[6] which aims to simulate an entire community of language agents, each with their own backstory, personality and goals. Language agents can also observe and take actions in the physical world, Instruct2Act[5] introduces the idea of building language agents that use robot embodiment to observe and act on the real world based on a provided goal.
While these applications show great promise, using them in real world scenrios still remains a challenge. LLMs are not trained to be used as agents to plan and act, they are designed to be interactive chat systems. This makes it challenging to use them as language agents, becuase thats not they were tuned for.
Most language agents prompt off-the-shelf language models for convinience and flexibility, this is the most used framework for developing language agents, systems like Voyager, ReACT, Plan-Execute, LLM-Compiler, ProgPrompt etc all use the same approach to configure a model to behave in an agentic way through complex prompting.
Finetuning allows us to customize the structure of the output of LLMs, this is usually used to provide a language model with domain specific knownlege to be applied to a specific industry or domain, finetuned models have been shown to outperform prompted larger language models for specific reasoning tasks while reducing inference and expense. GorillaLLM[4] uses a base LLM and finetunes it on open APIs which allows the language model to learn how and when to utilize those APIs when given a prompt by a user. This is an important step in building agent specific LLMs considering tool usage is an important aspect of building language agents.
FireAct combineds research in langauage agents and agent fine-tuning [1]
FireAct[1] takes this idea further by finetuning an LLM using ReAcT trajectories of agentic task completion. The aim is to build LLMs which respond and reason following the defined ReAct framework, making them cheaper, accurate and stable in real world applications. This approach aims to solve controlability and repoducability, which remain the biggest challenges in building LLM applications.
The FireAct paper uses a setup of question answering using the Google search API to explore a variety of language models and prompting techniques in order to achieve higher performing lanugage agents. The study uses 500 accurate agent trajectories genrated by GPT-4 to finetune smaller language models. For example, fine-tuning Llama2-7B with 500 agent trajectories generated by GPT-4 leads to a 77% HotpotQA performance increase.
FireAct accomplishes this by fine-tuning a series of language models which include Llama2-7B, Llama2-13B, CodeLlama2-7B, CodeLlama2-13B, CodeLlama2-34B and GPT-3.5. Each of the language models are finetuned using the following prompting strategies:
- ReAct
- ReAct + Chain-of-Thought
- ReAct + Reflexion
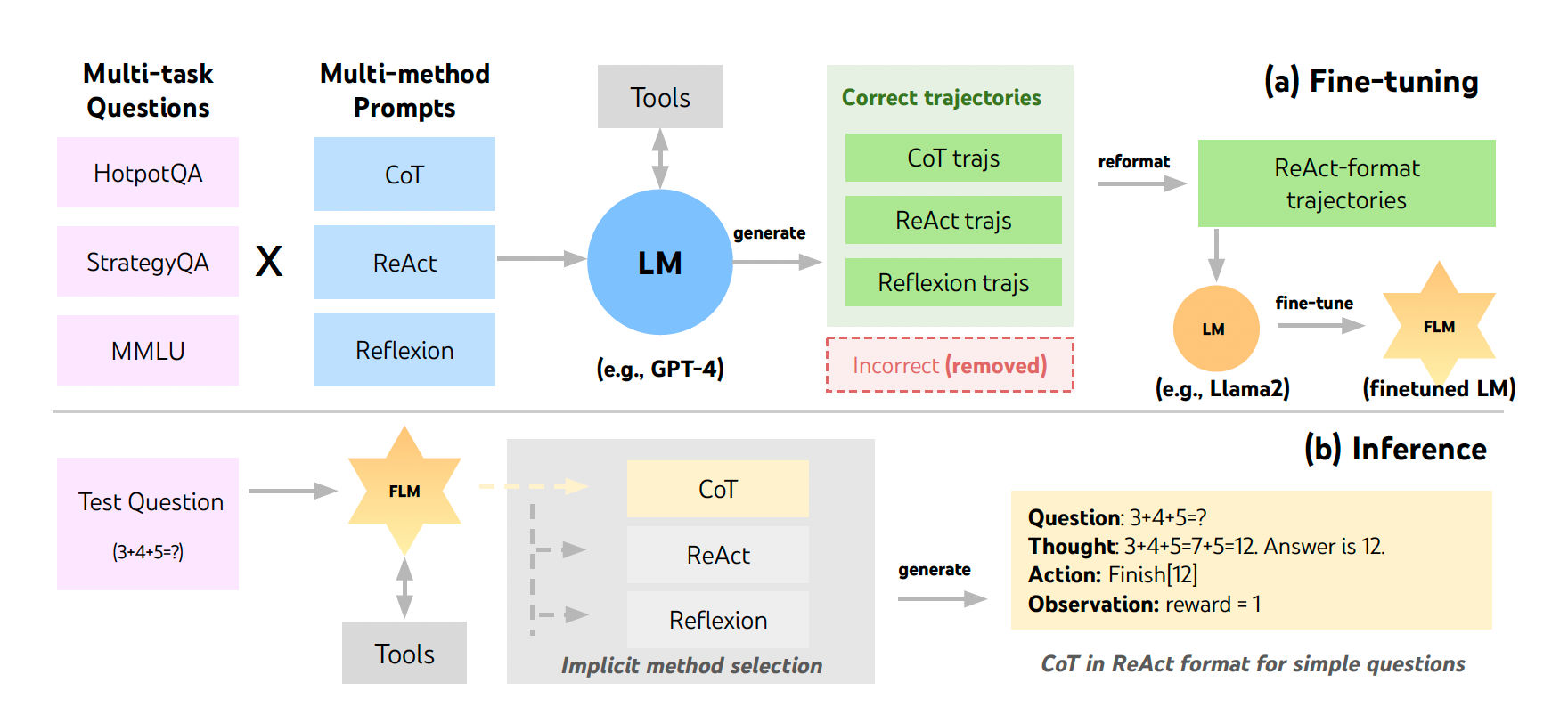
FireAct Architecture: FireAct combines prompting techniques for ReAct, ReAct+CoT, ReAct+Reflexion to generate trajectories using GPT-4 to finetune smaller language models [1].
Since we have already covered the ReAct framework, I'll briefly describe what Chain-of-Thought and Reflexion add to the base ReAct framework.
ReAct with Chain-of-Thought
Chain of thought prompting urges the language model to perform intermediate reasoning steps in its trajectory generation when completing a task. These are known as reasoning traces, this urges the language model to "think step by step" by thinking about each previous step it has completed towards accomplishing its goal.
ReAct with Reflexion
Reflexion prompting adds a requirement for the language model to reflect on its previous steps towards its goal, this enables the language model to avoid the infinite loop problem where the model spirals out of its task due to error propagation during an intermediate step. The the FireAct fine-tuning the reflection is used on the 6th and 10th prompting round in the generated trajectory.
For the experiments, the authors use HotpotQA, Bamboogle and StrategyQA to generate agent trajectories using GPT-4 and also to evaluate the performance of the fine-tuned models.
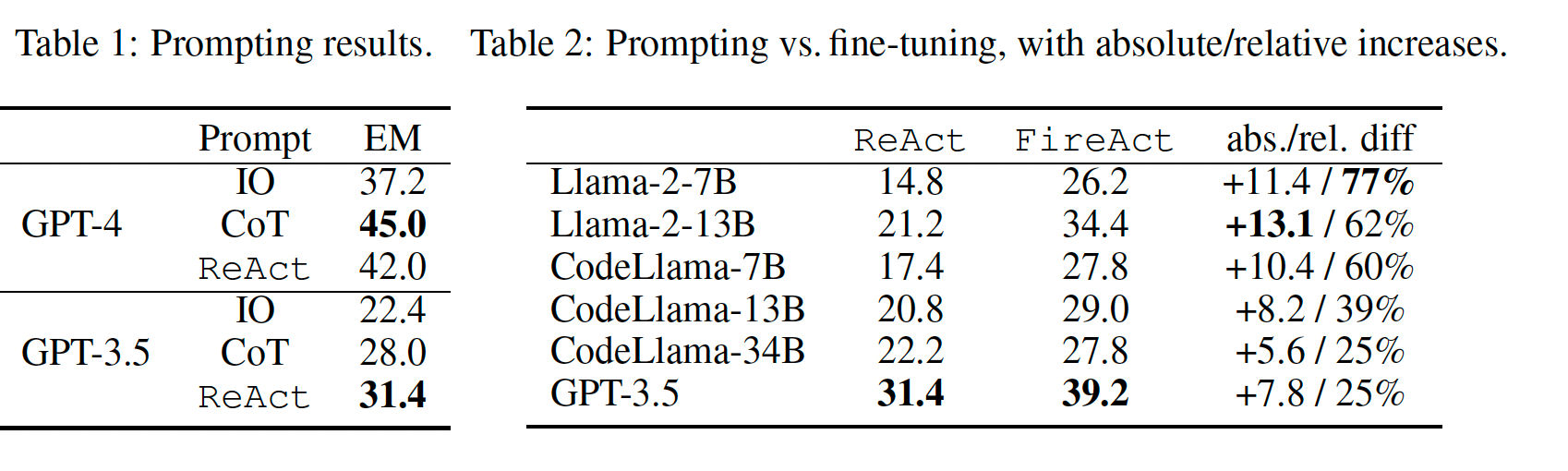
FireAct Architecture evaluation results[1]
The results show that while the fine-tuned models do not reach GPT-4 reaoning performance they are able to reach significant performance impromvement by fine-tuning language mdoels on agent trajectories. This is most evident in the smallest model categories (7B) which saw the highest performance increase in the finetuning process. The results also show that the performance of the model after fine-tuning does not always correlate with the number of model parameters. This can serve as a guide when gathering pretraining data for training language models which will be used within agent frameworks.
While FireAct is the first research endovour to formally approch the problem of combining fine-tuning research and language agents, it is worth mentioning that there have been other projects that have built or are building LLMs to be used as agents, some notable mentions are Large Agentic Model by SuperAGI[3], Large Action Model by Rabbit research [6] and Adept's ACT-1 which is a tranformer for actions [7].
The FireAct paper focuses on finetuning language models to follow the ReAct agent framework, this leaves room for future research to explore the application of this fine-tuning approach to other agent frameworks such as Plan-Execute, Tree-of-Thought or maybe even new procedural formal languages for defining action and reasoning trajectories in a single prompting step.
References
- FireAct paper
- ReAct framework
- SuperAGI's large agentic models
- Gorrilla LLM
- Instruct2Act paper
- Generative Agents
- Rabbit Large Action Model
- Adept AI ACT-1
Last updated at: March 3, 2024