Original date published: March 10, 2024
Foundation Models for Robotics Series Part 1- Introduction
First part of a series covering the use of Foudation Models in Robotics, we discuss application areas and the RT-2 model as an example to show the use of those application areas
I'm starting my first blog series which covers the use of foundation models for various areas in robotics. This series is to serve as a personal guide for my journey as well as overviews for readers who are interested in discovering how to build and apply foundation models in robotics.
Foundation models are models that have been trained extensively on large internet-scale amounts of data to solve a specific type of machine learning problem, they are not trained to be problem specific but to generalize to a wide range of problems within a machine learning approach [1]. The approach of training foundation models is really powerful because it allows us to finetune these base models to be used in a particular downstream task, domain or use-case while retaining their generalizability from pre-training.
Traditional deep learning models in robotics are trained on small datasets tailored to a specific task, which limits their ability to be used in diverse tasks. As an example Deep Reinforcement Learning which has up until this point been the most popular approach for training deep learning models for robotics applications allows the model to learn how to operate in a single environment or a single problem, it is impossible to use this models outside of the specific domain they were trained for, examples of this approach are AlphaGo[2] and OpenAI five[3].
Foundation models enable us to train models that generalize to different applications, tasks and embodiments using the same foundation model.
Foundation models can be applied to robotics broadly in the following areas:
- Perception (High-Level planning and Low-Level Planning)
- Planning
- Manipulation
- Navigation
There have been research projects that have explored the use of foundation models in each of these areas. In these series we will be traversing between each of these application areas in no particular order.
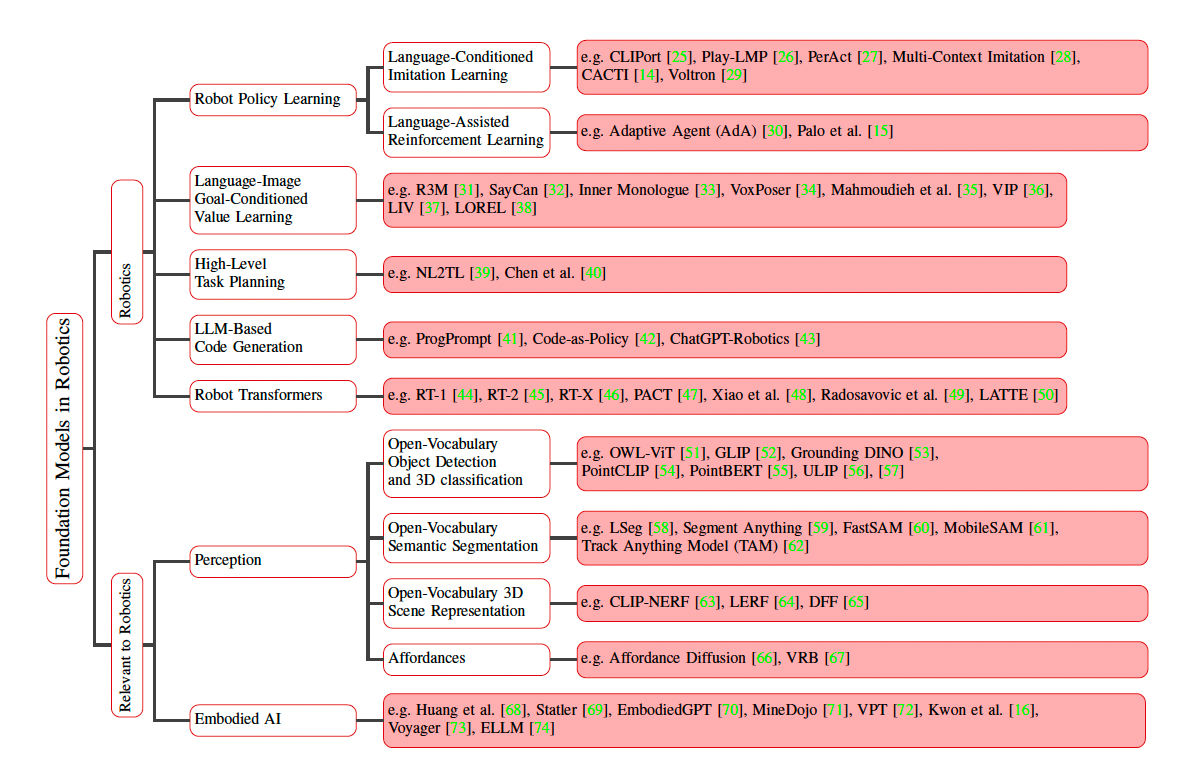
Map of Appliation of Foundation Models in Robotics[4].
The transformer architecture[5] has made it build and scale foundation models in various areas by increasing the amount of compute hardware and/or data. The initial training process of is then followed with post training processes such as instruction tuning and in some cases RLHF (reinforcement learning with human feedback). This approach has become common place with the proliferation of large language models such as ChatGPT, LLaMa, Mistal, Phi etc. These LLMs can then be further tuned to more domain specific application while retaining its pre-training reasoning and generalizability.
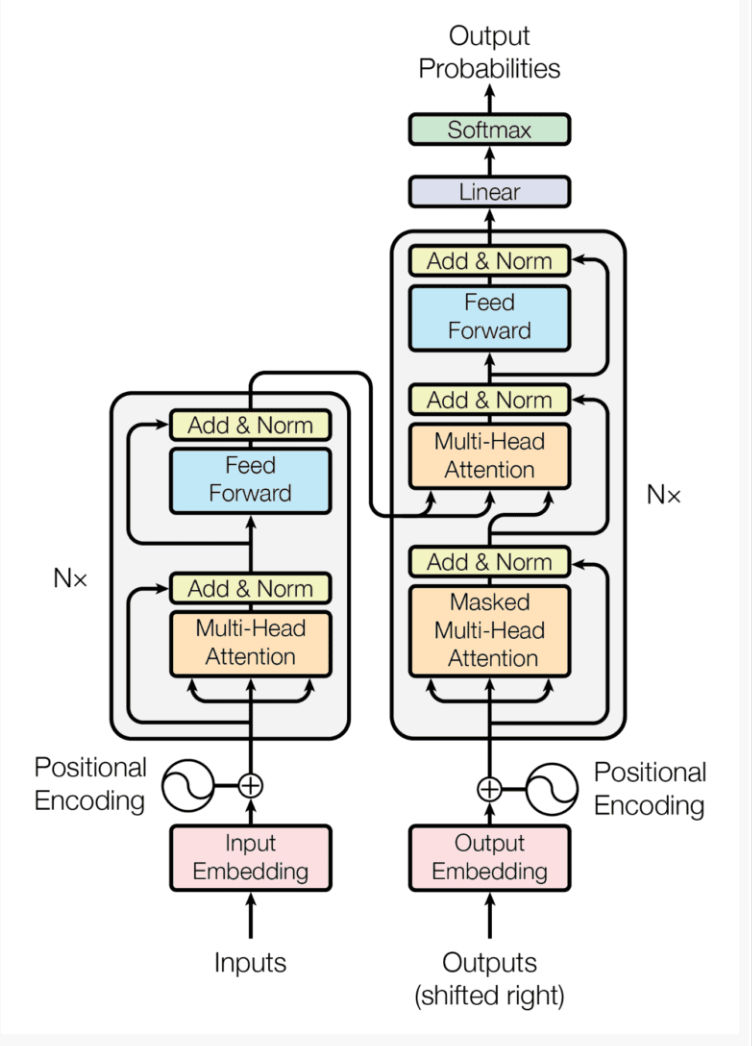
The Transformer Architecture Diagram[5].
In robotics, we make use of the following kinds of foundation models :
- Large Language Models (LLMs): LLMs are a type of foundation models which a trained on large corpus of text and are used to produce language output through next token prediction. The most common approach for building LLMs is through the decoder only transformer architecture.
- Vision-Language Models(VLMs): VLMs are foundation models which are trained to use both text and images as input, this is achieved through the use of contrastive learning to building mapping representations of both images and language tokens. These models also produce natural language as output through next token prediction.
- Vision-Language Action Models (VLAs): VLAs are foundation models similar to VLMs which are trained to use both images and text as input, the modification in this architecture is that they are also able to generate action tokens which describe a specific control instruction to an embodied agent either through a physical robot or software agent.
- Audio-Language Models (ALMs): ALMs are foundation models which use a combination of stream of audio sequences and text tokens to generate an output text sequence using next token prediction.
- Visual Navigation Models (VNMs): VNMs are foundation models which take an image stream an input and produce an navigation action sequence to reach a target location.
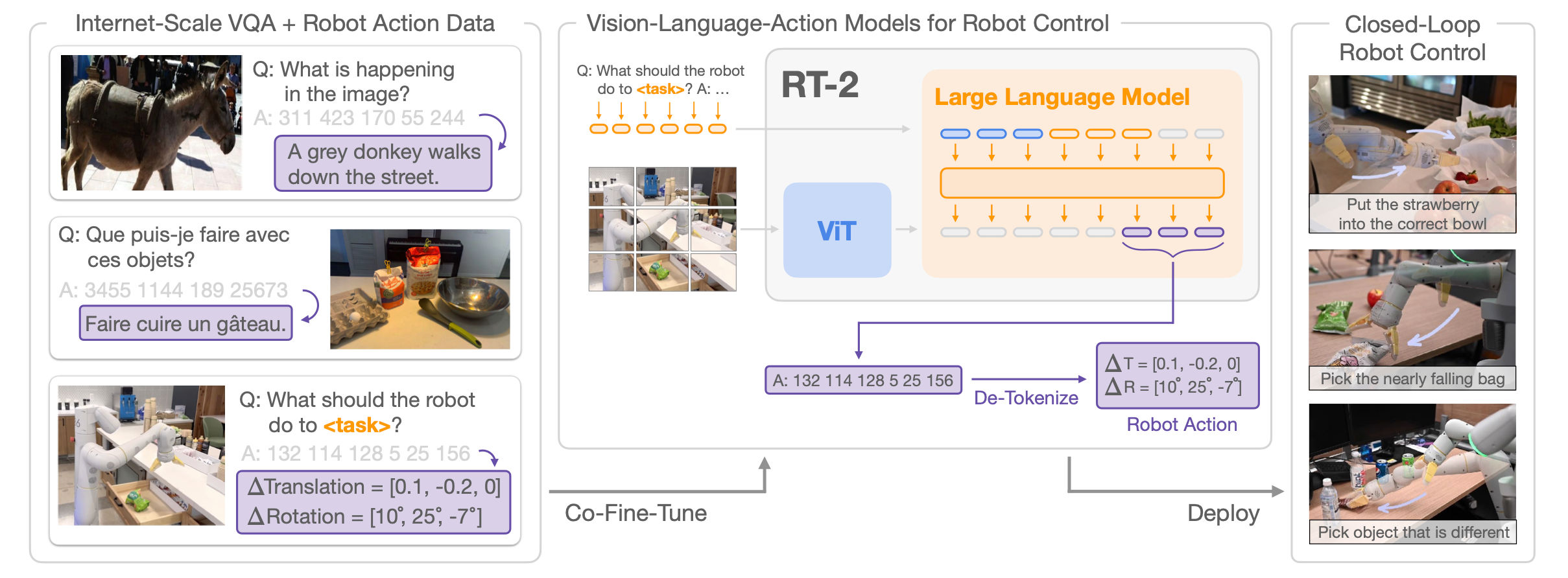
RT-2 VLA Model[6].
For starters we will discuss RT-2[6] as an example to guide future discussions
about foundation models in robotics. RT-2 is a multimodal foundation model from Google DeepMind
which uses input as both language and images, and it generates not
just english language but robot language tokens for taking actions.
The RT-2 was trained on both language image pairs, but also embodied
robotics action data. Its important to highlight that an approach like RT-2
combines perception, semantic understanding (planning) and action into a single model.
This allows the model to understand objects it has not seen before, understand broad concepts such as making
coffee as well as the low-level action sequence required to perform the manipulations required to “make coffee”.
Let's break this down a bit further. RT-2 is one of the models that offers an end-to-end approach for robotics.
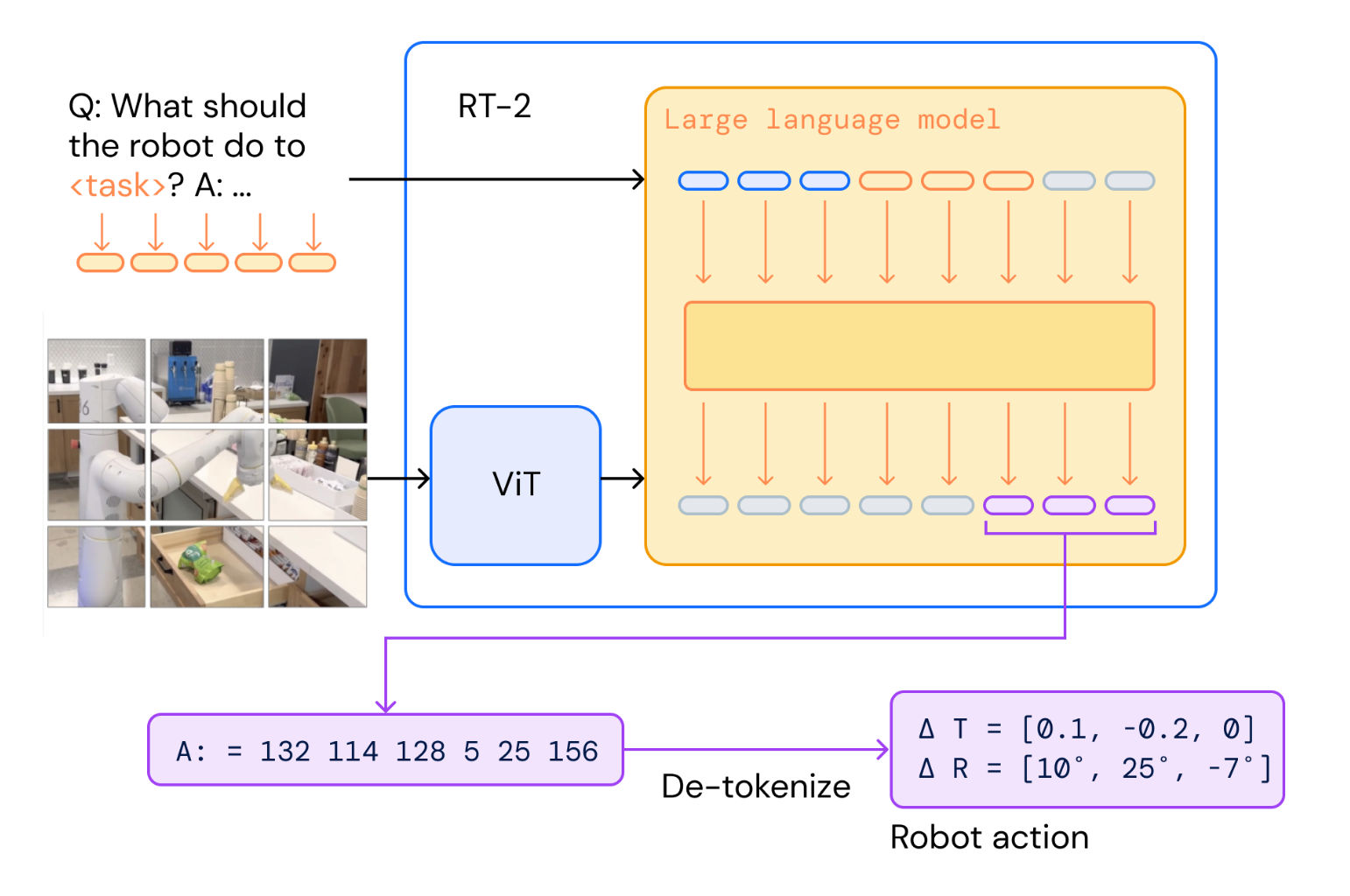
RT-2 Architecture[6].
Perception is handled by the vision component in the VLA architecture, this uses object generalization learned from training on a large amount of images similar to CLiP[7] and Palm-E[8]. Some other approaches build the perception module separately using a Vision Transformer (ViT) architecture [9] and use natural language as the communication medium, we would be covering this in more detail in future articles in this series.
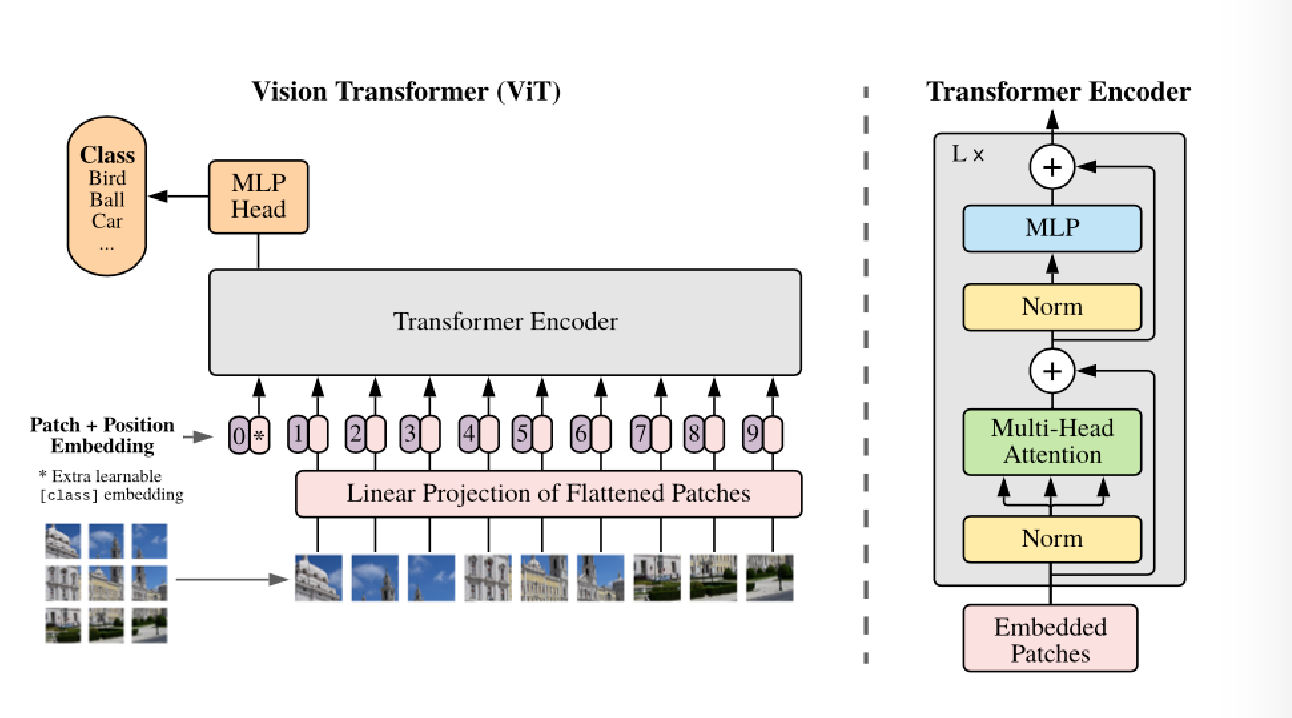
Vision Tranformer Architecture[9].
Planning is handled through the semantic understanding, reasoning and generalizability common in LLMs such as GPT-4, the model can be given an abstract problem or instruction and provided with enough state context can decided on the constraints and steps required to accomplish that task. This approach is also used solving Navigation problems.

RT-2 plans based on high level instruction[6].
Finally Manipulation involves generating sequences that control the joints or provide pre-defined high-level instruction on how to execute the generated plan on the robot hardware, this is done the the 'action' part of the VLA, where the model is trained with special tokens which define actions that can be performed by the robot, during the training process the model builds a semantic understanding of each action and their effects.

RT-2 Action Token Generation[6].
RT-2 is a unique example in that it is one of the few approaches that integrate all these problems into a single model. As we discuss other approaches in this series we will see how some projects chose to focus on a few of these problems by combining various foundation models together and defining a medium of communication between these models to execute an language instruction.
While RT-2 does not focus too much on its post-training processes, a logical next step for this approach would be to enable fine-tuning the RT-2 model for specific robot hardware embodiment (quadruped, humanoid, differential drive etc) and building a reward model to validate the task execution of the model by following RLHF procedures [10].
I'm really excited for this series and want to get it right, there is so much to share and many downstream applications, these ideas can be applied beyond robotics and autonomous agents. I would also appreciate if you could provide feedback on the blog post. I would like to learn your thoughts on the series, did you learn something new? should I go more technical? should I go less technical? should I add more references or discuss everything in the posts? should I make the posts longer or shorter? I'd love to hear what you think. Thank you for making it this far, I hope you as excited to read the next part of this series as I am to write it.
References
- Standford Center For Fondation Models Report
- Google DeepMind AlphaGo
- OpenAI Five Dota Model
- Map of Application of Foundation Models in Robotics
- Transformer Architecture Explained
- RT-2 Foundation Model
- OpenAI CLiP model
- Google DeepMind Palm-E
- Vision Tranformers
- How is AI helping to Advance Robotics? - Vincent Vanhouke
Last updated at: March 10, 2024