Original date published: March 16, 2024
Foundation Models for Robotics Series Part 2 - Foundations
Second part of a series covering the use of Foudation Models in Robotics, we discuss some fundamental concepts and building blocks for building foundation models.
Foundation models have billions to trillions of neural network parameters and are pre-trained on massive internet-scale datasets. Due to the size and scale of these models they can become very computationally expensive. The computational processing requirements for training such models are in the zeta flops of compute on specialized hardware such as GPUs or TPUs, as well as highly specialized software infrastructure for training such large models [2]. Therefore these models are used as reusable components/modules which can then be fine-tuned for a specific application use case and downstream tasks, this process can also be referred to as adaptation [3].
In this part of the Foundation Models for Robotics series we will be breaking down the architectural components of these models and description of the some approaches used for the construction of foundation models.
Terminologies and Preliminaries
This section focuses on explaining the building blocks and the basic mathematical details for building foundation models. We would begin with how the inputs are broken down to be used as inputs for the foundation models.
Tokenization: Given a sequence of characters, tokenization is the process of dividing the sequence into smaller unites called tokens, these tokens can be as small as characters or as long as words [4].
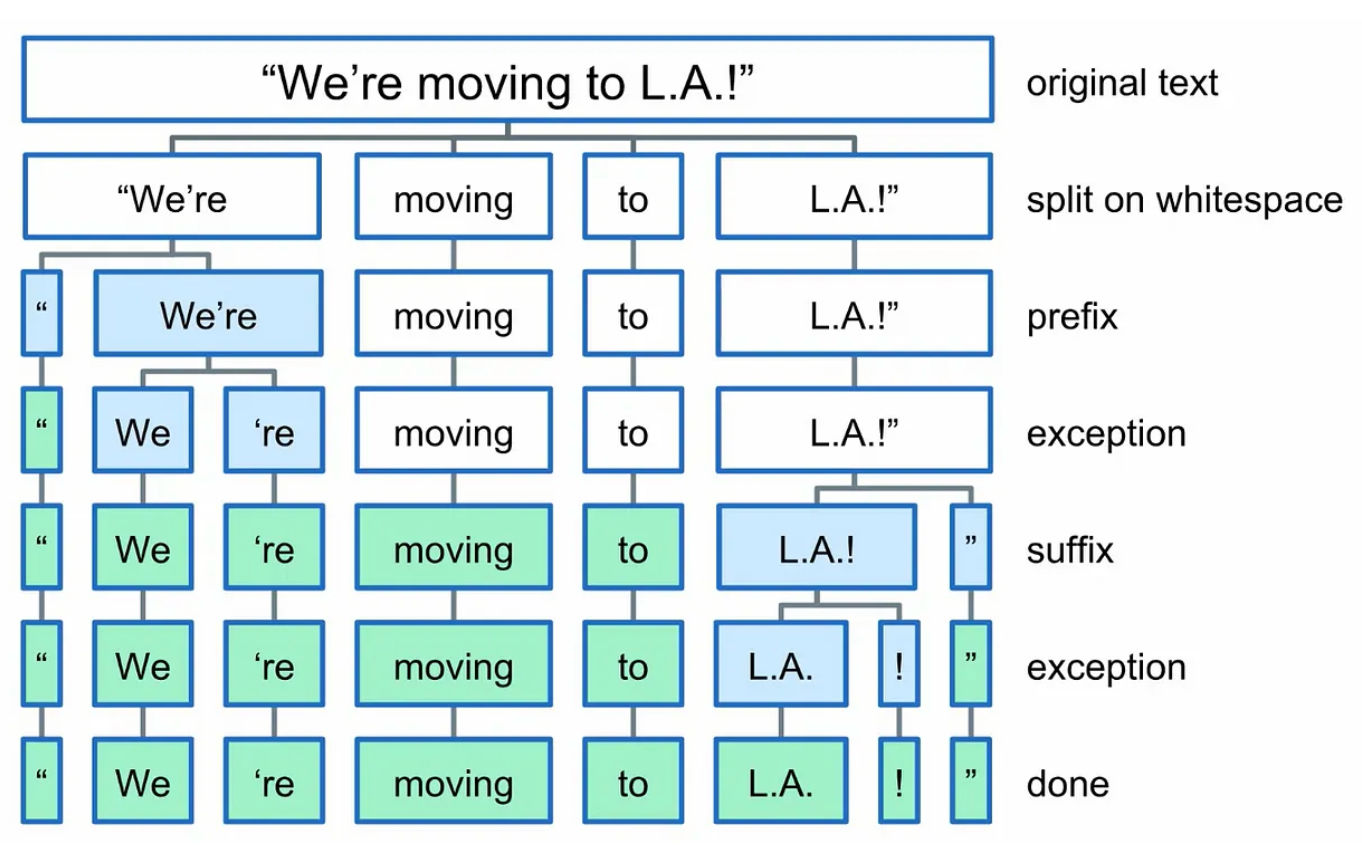
Tokenization example [4]
In the context of text, tokens can be broken down using different strategies, they can be characters, segments of words, complete words or portions of sentences. Tokens are then represented as 1-hot vectors of dimension of the total vocabulary.
The tokens are then mapped into a lower-dimension vector of real numbers through a learned embedding matrix. An LLM takes a sequence of these embedding vectors as raw inputs, producing a sequence of embedding vectors as raw outputs.
Finally the output vectors are mapped back to tokens. This is how language models such as the GPT series and the LLaMa series work [5]. GPT-3, for example was trained on a vocabulary of 50,257 different tokens using a byte-pair tokenization strategy, and an embedding dimension of 12,288.
The token decoding process is not deterministic so there is a probability distribution over the possible output 1-hot vectors. This creates a weighting for each option in the 1-hot vector. The weightings are then used by the LLMs as probabilities over the tokens.
This adds randomness in the text generation process. For example the temperature parameter in GPT-3 specifies how the model should select a token based on the probability distribution i.e in the case of 0 temperature the model selects the token with the highest probability.
Byte-pair encoding is the token encoding scheme used in the GPT family of models [6], it is also the most common encoding scheme in building language models. Byte-pair encoding starts with a token for each individual symbol (e.g letter, punctuation) then recursively builds tokens by grouping pairs of symbols that commonly appear together in the text corpus. The tokenization process can extend beyond text to diverse data modalities such as images, videos and robot actions. Aside from text, various other modalities can be represented as sequences, images can be represented as a sequence of image patches, robot actions can be represent the sequential nature of tasks for a robot.
Generative Models: Generative models are a type of machine learning model that sample from a probability distribution to create new examples of data that appear to be from the same distribution of the data used to train the model.
For example a generative model trained on landscape image data will not be able generate images of people in social interactions. The generative models can be trained to be conditional meaning that you can provide additional description about the kind of image you would like to generate which will be provided as context to guide the generation process. This is how image generation models like StableDiffusion [7] and DALL-E [8] work.
Discriminative Models: Discriminative models are used in regression or classification based problems. Most existing machine learning applications fall into this category of models, they are designed to use a set of input features (x) to predict an output target (y) by learning a distribution provided in the training data, once trained they then map an input to this learned distribution to predict an output. In contrast to generative models, discriminative models are used to identify groups and categories from existing data using the learned distribution. The emphasis is in the validity of the categorization or predicted target.
Transformer Architecture: We briefly discussed the transformer architecture on the previous post of this series but we did not discuss the underlying technical details of this architecture.
As stated in the previous post, most foundation models are built using the transformer architecture, which has been instrumental in the rise of foundation models. A transformer acts simultaneously on a collection of embedded token vectors (X1....Xt-1) known as the context window.
The enabling innovation of the transformer architecture is the multi-head self-attention mechanism which allows the model to gather information from all the input embeddings while maintaining multiple focus areas [9].
![Multi-head query attention, each worker describes a separate attention head which focuses on a different aspect over the entire sentence context [9]](https://ik.imagekit.io/generalcognition/multiqueryattention.png)
Multi-head query attention, each worker describes a separate attention head which focuses on a different aspect over the entire sentence context [9]
In this architecture each attention head computes a vector of importance weights that correspond to how strongly a token in the context window Xi relates to other embedded tokens within the same context window. Each attention head mathematically encodes different notions of similarity. Each head can be trained and evaluated in parallel across all tokens and across all heads, leading to faster training and inference when compare to previous sequence model architectures such as RNNs and LSTMs [10].
Attention maps each token embedding to every other token embedding in the context and finds the similarity between them, the similarities between the tokens are then measured through a scaled dot product. The output of the attention for (i)th position is then given as a sum over values weighted by attention weights. One of the key reasons for the success of transformers is that this process can be parallelized through specialized hardware such as GPUs or TPUs. This is done by abstracting the attention process into a series of matrix multiplications. The operation are stacked to form attention layers and are grouped into logical blocks which are Encoder and Decoder. These logical blocks form the transformer. The size of a transformer model is determined by the size of the context window, the number of attention heads per layer, the size of the attention vector in each head and the number of stacked attention layers in each block. Transformers are often used as sequence predictors although there is no architectural requirement that dictates it needs to be used in that manner.
Autoregressive Models: Autoregression is a representation of a random process which its output causally depend on its previous outputs [11]. Autoregressive models use a window of past data to predict the next token in a sequence. When the model predicts the output it then ingests the latest predicted output and removes the oldest predicted output, the number of previous outputs it holds to make its predictions is based on the window of the autoregressive model. RNNs and LSTMs are deep learning architectures which use autoregression to make predictions about their next output, while transformer models are not autoregressive by nature they can be adapted to use an autoregressive framework for next token prediction. This is the approach used by most LLMs today.
Masked Auto-Encoding: Masked auto-encoding is a technique introduced to train the model to understand the contexts within a sentence [12]. It involves 'masking' certain parts of a sentence and setting a training objective for the model to predict the hidden tokens. This helps the model to think within the context of the sentence provided and understand the relationship between the tokens which define the context. Masked auto-encoding is used to train transformer models such as BERT [13].
Contrastive Learning: Visual-Language Models are trained differently from language models. The are trained to learn a joint representation of multiple modalities in this case images and text this is known as contrastive learning [15]. The object function for training the model is to group items with similar semantic meaning together irrespective of their modality. This could mean grouping cat images together with text describing cats or cat information within an embedding space. Contrastive learning is used to build visual language foundation models such as CLiP [14].
![Contrastive learning aims to group similar inputs together across modalities by learning a joint representation [15]](https://ik.imagekit.io/generalcognition/contrastivelearing.png)
Contrastive learning aims to group similar inputs together across modalities by learning a joint representation [15]
Diffusion Models: Diffusion probabilistic models are a type of generative models that are trained on a two part process an iterative forward process and a reverse process [16]. The forward process involves iteratively adding gaussian noise to an input until the input is completely noise, the reverse process is for the model to reconstruct the initial input from the noise by iteratively de-noising the data. This training objective enables the model to create new examples within the distribution of the data it was trained on from random gaussian noise. These models can be conditioned such that they can generate new samples based on context provided. This is what is used to build image generation models such as StableDiffusion[7] and DALL-E[8].
![Diffusion models noising and de-noising process [16]](https://ik.imagekit.io/generalcognition/diffusion-noisinganddenoising.png)
Diffusion models noising and de-noising process [16]
In this part of the series we covered the fundamental algorithms used in building foundation models, and we covered various foundation model approaches and techniques. We will continue the series by exploring different types of foundation models that exist today and go into more details as to how they can be applied to robotics.
References
- Foundation Models in Robotics
- Meta's Generative AI infrastructure
- Robot learning in the era of foundation models
- Introduction to tokenization
- Building blocks of LLMs
- Byte Pair Encoding algorithm
- Stable Diffusion model
- OpenAI DALL-E model
- Attention mechanism Explained
- Introduction to RNNs and LSTMs
- Autoregressive models explained
- Masked Auto-Encoding
- BERT model
- OpenAI CLiP
- Contrastive Learning explained
- Diffusion Models explained
Last updated at: March 16, 2024