Original date published: March 29, 2024
Foundation Models for Robotics Series Part 4 - Robot Decision-Making, Planing and Control with Foundation Models
In this post we will cover decision-making, planning and control and how foundation models have the potential to serve as valuable tools for enhancing robotic capabilities.
In this blog post we will cover decision-making, planning and control and how foundation models have the potential to serve as valuable tools for enhancing robot learning capabilities.
Vision-language goal-conditioned policy learning, whether through imitation learning or reinforcement learning hold promise for improvement using foundation models. Language models also play a role in offering feedback for policy learning techniques,
this feedback loop can foster continual improvement of the robot decision-making as the robot refines their policies based on the feedback provided by the language model. An example of such work is the Eureka model which uses a human level
reward design algorithm powered by LLMs for training a robot policy using reinforcement learning [2].
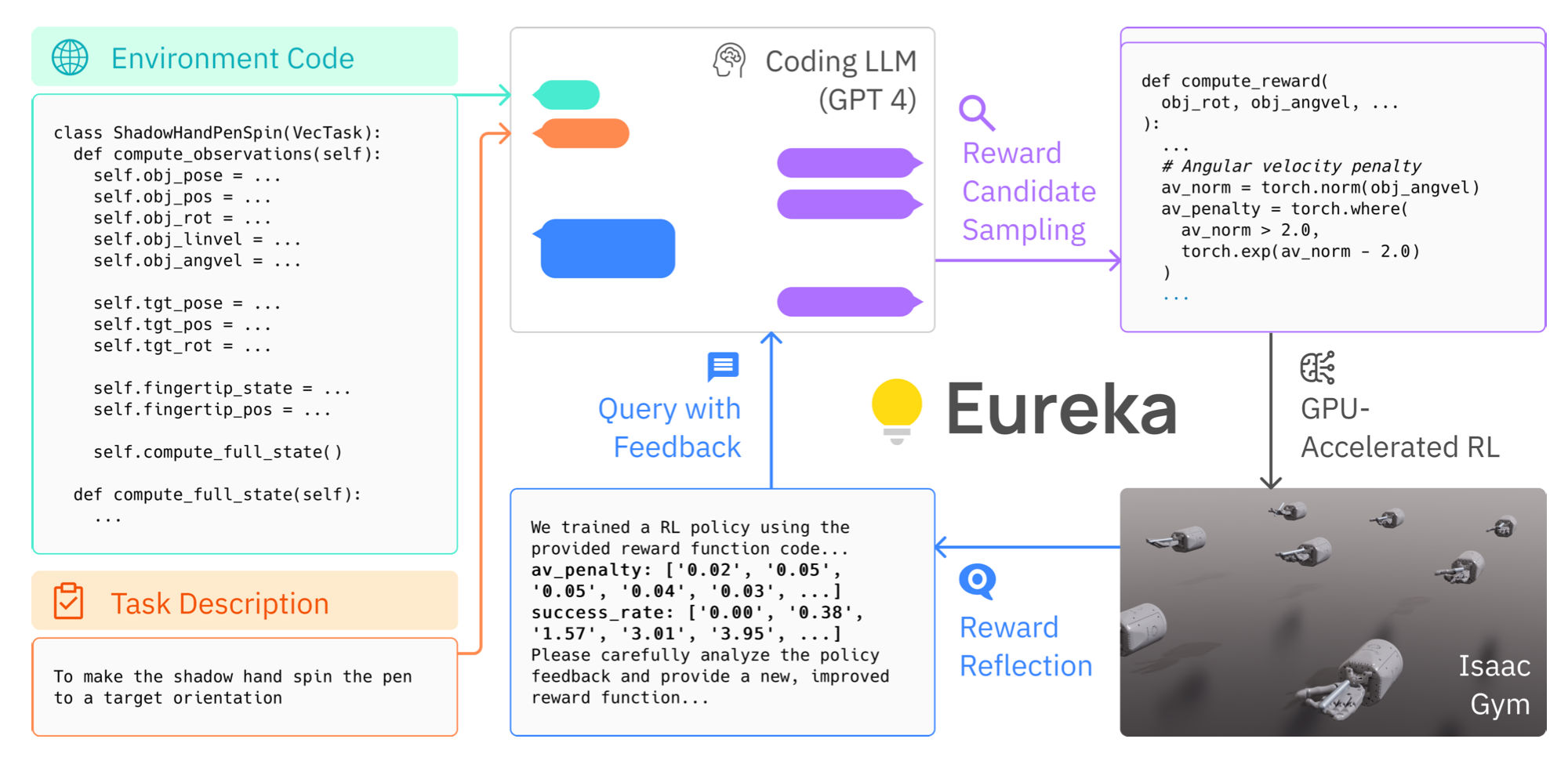
Eureka takes the unmodified environment code and the high-level task description in natural language and continually iterates to improve the reward code for training the RL algorithm [2].
In this post we will discuss robot policy learning and language-image gaol-conditioned value learning, we will cover current standards for training such models as well as how foundation models have been applied to improve the performance of these model architectures.
Robot Policy Learning for Decision Making and Control
In this section we discuss robot policy learning including language-conditioned imitation learning and language-assisted reinforcement learning.
- Language-Conditioned Imitation Learning : In language-conditioned imitation learning, a goal-conditioned policy is learned that outputs actions conditioned on the current state and language instructions. The model is trained using demonstration and the loss is calculated as the log-likelihood of selecting the right action at a particular time step following the policy conditioned on the current state and language instruction. The demonstrations can be represented as trajectories, or sequence of images, RGB-D voxel observations, language instruction are then paired with demonstration to be used as the training dataset. Each language-annotated demonstration consists of a state, and a language instruction and an action. The challenges in this domain are obtaining a sufficient volume of demonstrations and conditioning labels to train a policy, also distribution shift under closed-loop policy the feedback of the policy can lead the robot into regions of the state space that are not well-covered in the training data, negatively impacting performance. An approach to mitigate this challenge is to handle the demonstration data annotation challenge in language-conditioned imitation learning using foundation models. This involves gathering a diverse set of trajectories and using a foundation model to annotate the expected language instruction for performing that trajectory. CLIPort presents a language conditioned imitation learning policy for vision based manipulation [4]. CLIPort, a language-conditioned imitation-learning agent that combines the broad semantic understanding (what) of CLIP and the spatial precision (where) of TransporterNets [5]. CLIPort is an end-to-end framework that solves language-specified manipulation tasks without any explicit representation of the object poses or instance segmentation, but it is limited to 2D observations and action spaces. PerAct (Perceiver-Actor) aims to mitigate this challenge by representing observations and action spaces with 3D voxels [6]. PerAct takes language goals and RGB-D voxel observations as inputs to a Perceiver Transformer and outputs discretized actions by detecting the next best voxel action. Voltron presents a framework for language-driven representation learning in robotics [7]. Voltron captures semantic, spatial and temporal representations that are learned from from videos and actions. Deploying robot policy learning techniques that leverage language-conditioned imitation learning with real robots presents ongoing challenges, they are susceptible to issues related to generalization and distribution shift. To improve robustness and adaptability techniques such as data augmentation and domain adaptation can make policies more robust to distribution shift. Beyond language, recent works have investigated other forms of task specifications as MimicPlay, which uses human play data and low level motor command to condition the robot policy [8]. This allows the MimicPlay model to learn to perform new tasks based on one human video demonstration at test time.
- Language-Assisted Reinforcement Learning: Reinforcement learning is a family of methods to enable a robot to optimize a policy through interaction with its environment by optimizing a reward function. Unlike imitation learning, reinforcement learning does require prior dataset of demonstrations, and can theoretically reach super-human performance since it is not relying on human samples to understand its environment. Foundation models have been applied to the reinforcement learning algorithms in recent research which we will be covering in this section. Recent work by GoogleDeepmind proposes a unified RL architecture for foundation models which unifies reinforcement learning, VLMs, and LLMs. Their work focuses on addressing core RL challenges related to exploration, experience reuse and transfer, skill scheduling and learning form observation. The researchers use an LLM to decompose complex tasks into simpler sub-tasks, which are then utilized as inputs for a transformer-based agent to interact with the environment.
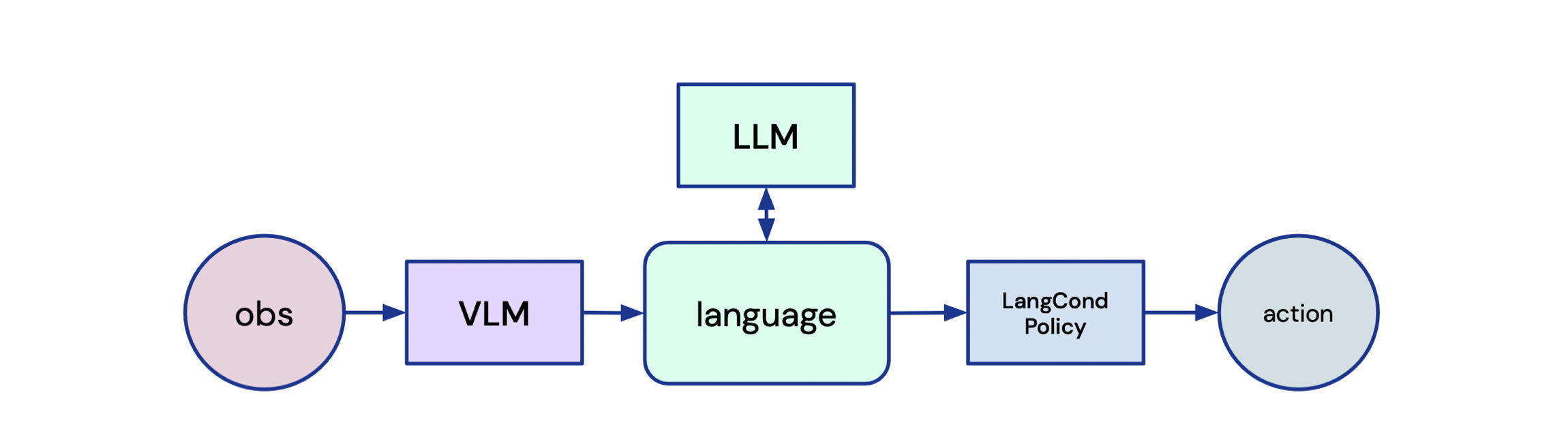
High level architecture of unified agent that combines reinforcement learning with foundation models (VLM and LLM).
Language-Image Goal-Conditioned Value Learning
In value learning, the aim is to construct a value function that aligns goals in different modalities and preserves temporal coherence. Value-Implicit Pre-training (VIP) employs time-contrastive learning to capture temporal dependencies in videos, but does not require video language alignment [10]. VIP is focused on robot manipulation tasks. Language-Image Value Learning (LIV) is a control centric vision-language representation which generalizes the prior work VIP by learning multi-modal vision-language value function and representations using language aligned videos [11]. The LIV model is pre-trained on arbitrary video activity datasets with text annotation, and the model can be fine-tuned on small datasets of in-domain robot data to ground language in a context-specific way. Both VIP and LIV learn a self-supervised goal-conditioned value function objective using contrastive learning. Value functions can be used to help ground semantic information obtained from an LLM to the physical environment in which a robot is operating. In SayCan [12], researchers investigate the integration of LLMs with the physical world through learning. They use the language model to provide task-grounding(Say), enabling the determination of useful sub-goals based on high-level instructions, and a learned affordance function to achieve world-grounding(Can), enabling the identification of feasible actions to execute the plan.
Conclusion In this part of the series, we considered how foundation models have been applied to imitation, reinforcement and representation learning in robotics. We considered how foundation models such as LLMs and VLMs have been used to guide policy creation, how foundation models have been combined with existing policies to mitigate distribution shift and generalization issues, we also considered how policies could be used to guide the output generation of foundation models.
References
- Foundation Models in Robotics
- Eureka: High-level reward design using coding language models
- Policy adaptation from foundation model feedback
- CLIPort language-conditioned imitation learning
- TransporterNets: Rearranging the visual world for robotics manipulation
- Perceiver-Actor: A multi-task transformer for robotic manipulation
- Voltron: Language-driven representation learning for robotics
- MimicPlay: Long-Horizon Imitation learning by watching humans play
- Towards a unified agent with foundation models
- VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-training
- LIV: Language-Image Representation and Reward for Robot Control.
- SayCan: Do as I can, Not as I say
Last updated at: March 29, 2024